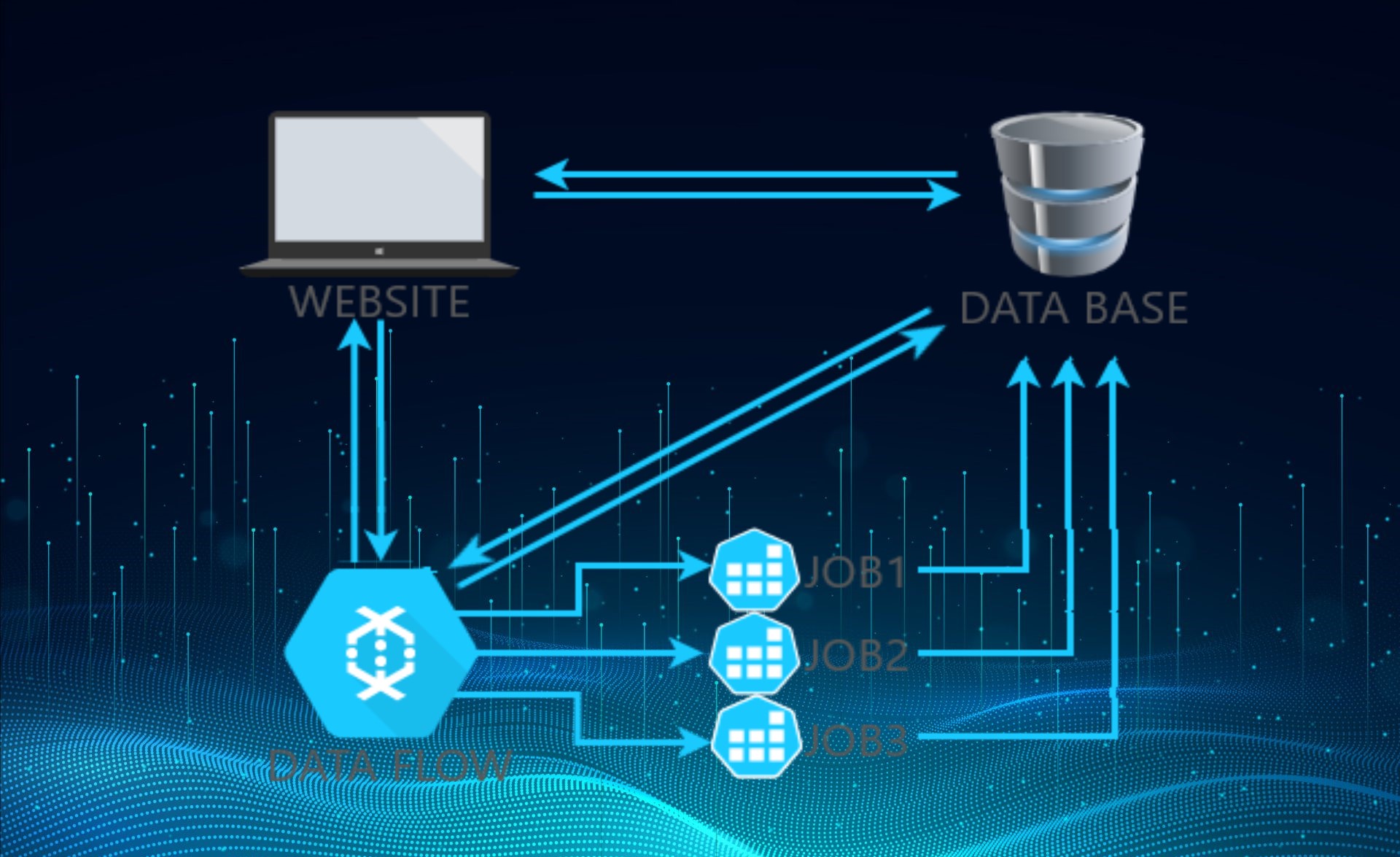

Big Data application handles requests (HTTP requests and messages) by executing business logic, accessing a database, exchanging messages with other systems, and returning a response. Logical components are corresponding to different functional areas of the application.
As with many technology implementations, over time, the systems gain added functionality and especially in the case of Big Data, higher velocity, variety, and volume. Legacy RDBMS cannot aggregate, store, and process this data efficiently or effectively, certainly not in high volumes. The data volumes are unprecedented and growing at warp speed. It resulted in low website speed and performance, poor user experience.
It was time to look for a better way of doing things. Adapting microservices architecture promised to keep our teams moving fast and offset these challenges.
It was proposed to develop a data flow-driven mechanism for microservices-oriented decomposition. Microservices architecture emphasizes employing multiple small-scale and independently deployable microservices, rather than encapsulating all function capabilities into one monolith, that slowed down the site speed and down customer requests.
So, what have we achieved? Instead of a single complex system, we have a bunch of simple services with complex interactions now. Clients’ website, Database and Data flow work separately, as loosely coupled services. Data flow-driven decomposition approach is rigorous and easy-to-operate with semi-automatic support.
All these and many other measures have been introduced with DevCom clients to optimize speed and have shown stunning performance results.
Additional Reading:



